

AffectedArc07
-
Posts
873 -
Joined
-
Last visited
-
Days Won
61
Posts posted by AffectedArc07
-
-
Warning - This is going to get incredibly nerd in places and I apologise. If you want clarifications in places, let me know.
Chapter 1 - The warning shots
For the past month or so, the server has been slightly unstable.
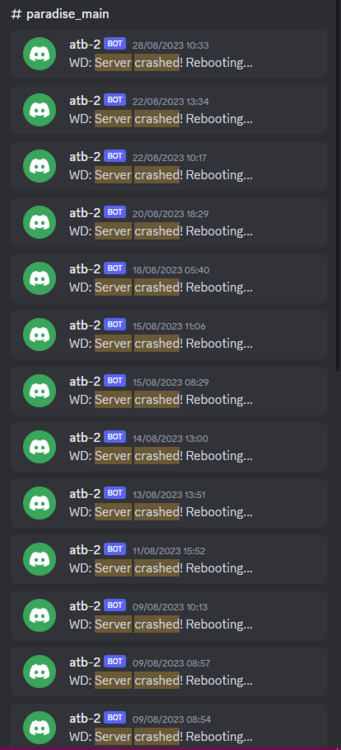
As you can see here, theres server Watch Dog warnings about a server crash. This isn't good, but I chalked it up to BYOND for the longest time as that was the status quo, with everything recovering fine afterwards. Little did I know of the storm that was brewing.
Chapter 2 - The first outage
As a lot of you probably remember, we had an outage on the 15th of August 2023.
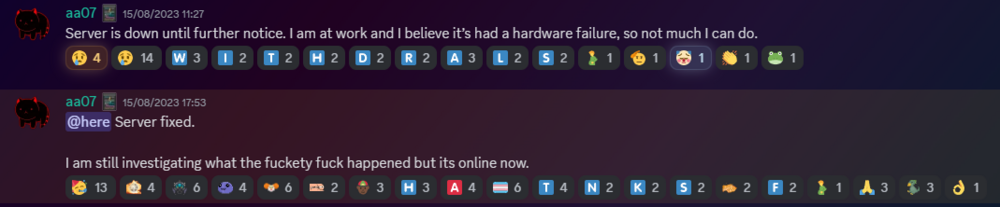
Before making this announcement, I assumed it to just be the game VM itself crashing due to windows kicking up the ghost, with the only real indication being that Corn was unable to login to the management VPN.
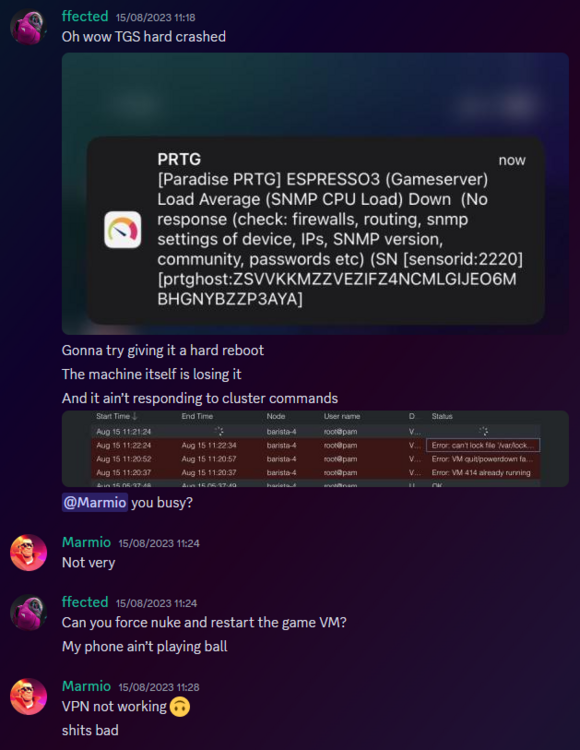
(For context - the management VPN is what gives access to all the Paradise virtual machines, similar to a work-from-home VPN you might have at your company). The fact that Corn couldn't even connect to this is what made me go "oh fuck its bad", especially with the hypervisor just not responding to stop commands, but after 6 hours and a full machine reboot (which it did itself), I assumed it was just a blip, and we moved on. However, this was indeed the calm before the storm.
Chapter 3 - The real catastrophe
Picture this. Its 10AM on a Monday morning (28th August 2023). You're lay in bed, enjoying a bank holiday (for the non UK people, we have bank holidays on random days in the year, which is basically a government mandated "ok its not a national holiday but you dont have to work" day), when I get the following message.
Unbeknownst to Adri, the entire server had just shat itself, hardcore.
A bit of background. Paradise is made up of 8 virtual machines running on the hypervisor (the server that runs the VMs). These consist of:
- A router for managing internal IPs and a management VPN (Own VM because pfsense + stability requirements)
- The core server with the database, ALICE, and about 10 internal automation tools (Own VM because its everything else)
- The webserver with the wiki, forums, and all the backend stuff (Own VM because its such a huge vector)
- The game server itself (Own VM because it needs windows)
- A server dedicated to Elasticsearch + Kibana for log & metric analysis (own VM so I can give Denghis the keys and leave him to it)
- An internal GitLab (Own VM to confine the fuck out of it)
- A PRTG runner for network monitoring (Own VM because it needs windows and its not going on the gameserver)
- A VM for Corn to make his stats thing
Anyway, I proceed to get out of bed and go to login to the server panel, only to be hit with a page timeout. So my next assumption is "oh its networking", but then I dig further and realise how fucked we are.
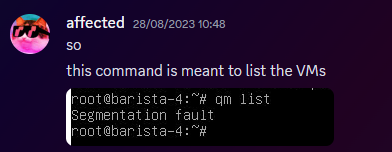
For those unfamiliar, a segmentation fault is when a program tries to read RAM it isn't allowed to. But thats not all! My next mentality is to try reinstall the Proxmox packages, so we can use the hypervisor again. Thats when I got a kernel error trying to merely run apt update.
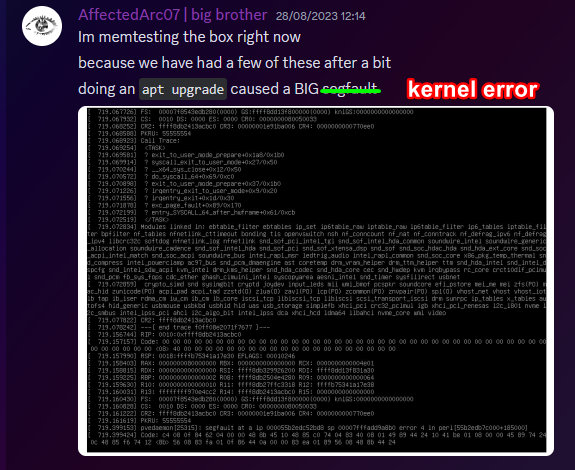
So as you can see, its already running bad. But wait. It gets worse!

I ran the same command (a version check) twice within the same second. One worked, one died instantly. The same also happened with a check script.
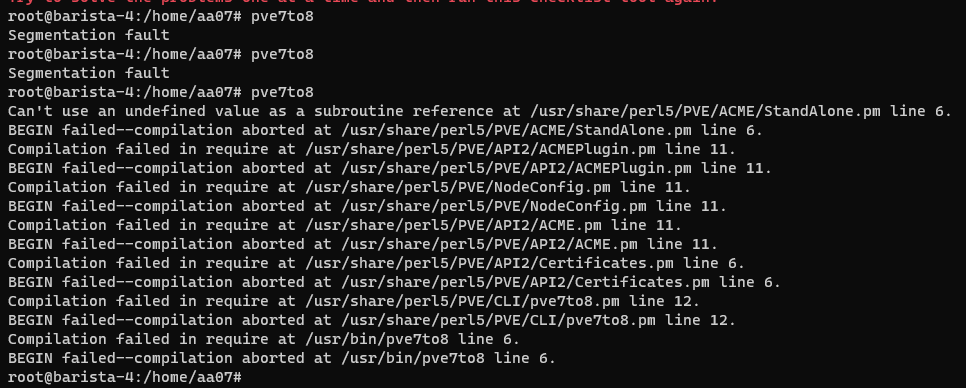
And trying to list VMs again, it worked half the time.
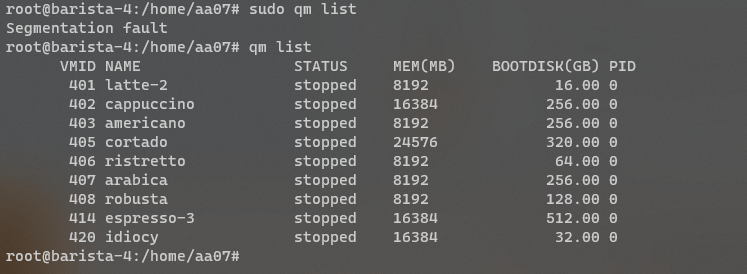
And above all, straight up corruption

So at this point, I establish there is something up, and do the logical thing of a memtest. Which it somehow passed.
So my next assumption is "Oh the OS is corrupt somehow, lets move the VMs off to get it fixed". This then unearthed a whole other pile of problems. Paradise has ~1.2TB of data, and all that has to go somewhere if you are wiping the disk, and the only backup I had on hand big enough was a storage share in germany, so I started backing up VMs to that.

If you do the maths, you can see that this will take a long time. So I then went to provision storage in eastern US, and at this point you can tell I was out of cares to give.
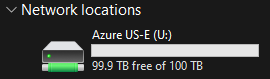
I needed fast, dependable storage, so I went to Azure. This helped. Considerably.
However, we were now 8 hours in, and the "oh god this is bad" mentality was setting in, especially with the server getting more and more unstable by the second.
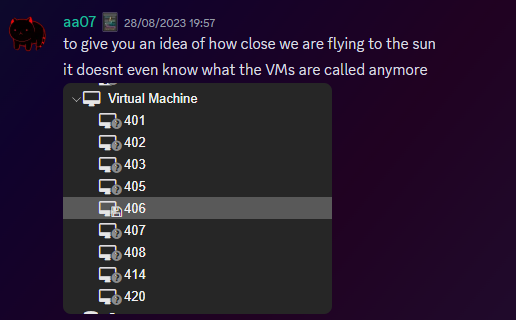
This dragged on, and we started to run low on time, which is when the "I ain't getting this done in a day" mentality set in, however I had all the VMs backed up, some in Germany, some in the US, and I was ready to reinstall the OS. So I grabbed a fresh copy of debian, the most stable thing I can get, and booted into the hardware console for the server, ready to reinstall.
That's when the debian installer segfaulted on me. I rebooted, it got past that, then died in a separate place. The RAM was fine, and neither of these segfaults were at point where a disk write was required, which led to finally point a finger at the CPU being fucked. It would line up with everything else, however at this point it was 1AM, I had work the following day, so I had to throw in the towel and go at it the following day.
Chapter 4 - The next day
I get home from work, and immediately get shopping for another server. There's another 13900K in stock, and I grab it. OS installs without a hitch, and notice the board is a new revision compared to our outgoing server (not just a different BIOS, a straight up different hardware revision). The main "oh this one is better" point was that I didn't have to blacklist half the motherboard modules this time.
For context server motherboards have extra features on them to help with management, such as a virtual monitor+keyboard+mouse so you can control it remote-desktop style remotely without an OS loaded. Its bloody neat. However, to get this board working on the old server, I had to make the OS completely ignore all these modules, otherwise it would hard lock whenever it tried to interface with it, which clearly isn't desirable behaviour.
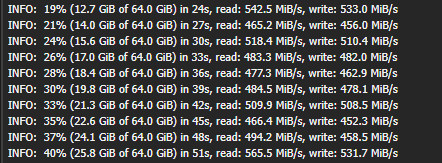
Anyway, I get proxmox installed, setup a basic bit of networking so I have a management VPN again, and then get to deploying the VMs. Which turned out to be a very, very slow restore process. Half of the VMs were stuck in Germany at this point, with a 1 megabyte restore speed, so I then went to move them from Germany to US-E to restore them faster. However:

This would take 8 hours. I dont have time for that. However, we have more Azure regions.
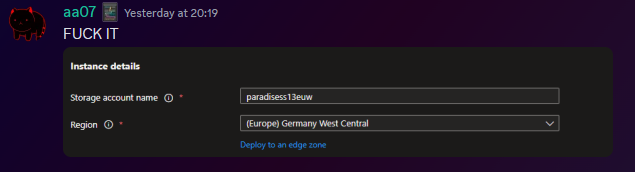
This helped. Considerably.
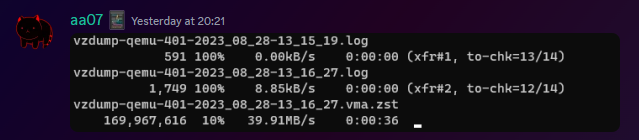
The final step was to get it moved from EU-W to US-E, which can easily be done with AzCopy, going via Microsoft's backbone instead of my own upload speed.

Anyway, enough backup talk, by this point it was restoring onto the new box, and I thought we had the light at the end of the tunnel. I even threw up the gameserver before everything else was ready because people had been patient and not bugged me, not to mention the support thrown my way (bless all of you who pitched in). I launched the server, stability checked it, then went to bed.
Chapter 5 - The light?
Day 3, I wake up, spin the last VMs up that I had left to restore overnight, did some quick validation, and all looked fine. No pings of downtime overnight, and I think we are finally sorted, so I leave for work and pretend all is fine.
I get home, and notice that TD is worse off than before. Like, 15% TD with 80 people, that is not a good amount when we can normally handle 150 people with about 1% TD, so I go to investigate clocks, and notice we are running at 3.4Ghz. Our target is 5.8Ghz, so theres a lot of performance missing here. Fast forward 3 hours of fucking with various power limits both in the OS and the BIOS, and I throw in the towel. I am beat. The server is running, but she isn't running optimally. Shes basically a car in limp mode.
Upon investigation, the CPU voltage fluctuates from as high as 1.08V all the way down to 0.72V, which for a 13900KF is very low. With little time to figure this out since I cant change BIOS settings without taking the server down, I bit the bullet and decided we can run on gimped performance now.
Chapter 6 - What now?
So we are running, but far from optimally. We are missing out on performance, but it runs, and I am in 2 minds of whether to investigate it. Intel 14th gen is rumoured to come out in September/October time, which lines up well with out upgrade schedule given its only a month or two away. There's also the option of RYZEN on the table still, with a 7950X not only being affordable on a better config for us ($200 instead of $300, and with more storage), so I guess we wait for what the tide brings us.
People have also mentioned that on kernel 6.2, the intel power state governer was modified, which may be the cause for this, since we were on 5.10 before.
I also want to take this to handle some points of criticism that came up during this
"Why is it down for 24 hours why arent you fixing it?"
Contrary to the stereotype, some of us have jobs, including me. Given I dont get paid for doing anything regarding hosting on paradise, theres a clear priority here to do actual work over para. Remember, I am a volunteer here, as are the headcoders, the admins, and everyone else. No one is paid here
"Why dont you have a team of people doing this?"
We dont really have an infrastructure team on this scale because its never really been required. I have Corn as a subordinate to manage stuff on the VMs themselves, and Denghis to handle the log analytics stack, but thats where 99% of it goes. Hypervisor management never really comes into play, nor does the hardware itself, hence why I never rolled out a team for it, and probably never will.
"Why dont you have a high availability setup?"
Simple - cost. Our server costs $300 a month. We are not doubling our monthly outlay for a box thats going to get maybe a days use over an entire year.
"Why dont you use cloud?"
This is a point I will actually expand upon. SS13 is not designed for cloud hosting, simple as. Most cloud PaaS offerings are for generic business things (See: Azure Logic Apps), and any PaaS hosting is always for webapps with 80+443 being your only exports. Theres also the issue with performance. No cloud provider will outfit machines with 13900K CPUs, its not viable for a multitude of reasons, and the single-core performance on xeon (which is what BYOND needs remember) is laughable compared to a standard Core-SKU CPU.
The other big hitter is bandwidth. We use 5TB of outbound bandwidth a month. On Azure this is $426 a month. On AWS this is $460 a month. And no, that doesn't include the server or any other resources. Cloud makes sense for businesses. We are not a business.
Chapter 7 - Closing notes
I just want to take a moment to thank everyone for sticking through this with me. This is undoubtedly the worst outage in Paradise history, and I do feel responsible since it rests on me, however you lot have been supportive through the entire thing and that has really helped me mentally wise. Thank you to all of you.
- aa07
EDIT - Forgot to mention
We've been through three of these boxes now.
-
 6
6
-
 22
22
-
 1
1
-
 1
1
-
 1
1
-
Quick sidenote because I don’t want to deviate massively
2 hours ago, Sonador said:I didn't DM a headmin because I assumed, like AffectedArc and the rules for ban appeals and admin complaints, it was at best frowned upon and at worst bannable.
The only reason I have such a problem DMing me is because on some days I would get 20+ people all with the most mundane questions like “thoughts on X?”, which could easily be conveyed over a ping.
The heads on the other hand have said on multiple occasions that you are free to contact them over any issues you may have, and actively encourage it instead of finger pointing posts like this.
That said.
2 hours ago, Sonador said:I didn't assume bad faith in my original suggestion
You absolutely did, you did it in the first sentence.13 hours ago, Sonador said:I know a bunch of the staff are going to come in here thinking I'm here to bitch about being rejected.
-
5 hours ago, falconignite said:
I might just make a new acct specifically for the wiki
I can set you an account password up, though at some point I should just make the signin passwordless with the same auth system you use to sign in with discord.
-
1 minute ago, Bargo said:
Alright, I can send an ID, but it'll be heavily censored since I very much do not trust anyone here with my address, ID number, and so forth. If you would be so kind as to show an example of what you would need to see on an ID in order for you to respect my rights to delete my information on here, that would be nice. Thank you.
It needs to be an ID that shows you are a resident of California, however its somewhat irrelevant, as I wish to bring a few other points to light.
Paradise Station does not meet the criteria for businesses that the California Consumer Privacy Act of 2018 applies to, namely we are not a for-profit business that does business in California nor do we meet any of the following thresholds:
-
Have a gross annual revenue of over $25 million (we make astronomically less than this)
-
Buy, sell, or share the personal information of 100,000 or more California residents, households or devices (of the 177,475 players we have in our database, America does not make up even 50% of it, let alone california)
-
Derive 50% or more of their annual revenue from selling California residents’ personal information (we make no revenue on the sale of information, we dont sell it)
Furthermore, Your publicly available web profiles, such as steam (which you link in your discord account profile) also state you are a resident of Texas, which would conflict with what you have stated above.
Also, if you have read our server TOS (which you are required to consent before joining), you would have seen the following clause:
You recognise that, due to the nature of the information collected, collected data may be retained indefinitely for the purposes of preventing fraudulent activity from occurring. Such fraudulent activity includes, but is not limited to: falsification of personal information, falsification of login credentials, and falsification of hardware details for ban avoidance purposes. This data includes, but is not limited to, game logs, IP and hardware information, as well as login information.
Given the above, we will not be deleting your data under the California Consumer Privacy Act of 2018.
-
1
-
-
Hi.
We can go the legal route with this, in which case we'll require ID that proves you are a resident of California.
Alternatively you can simply leave and never log into your account again.
Which would you prefer?
-
1
-
-
One design nitpick

I worry about the proximity of this to the zlevel transition border
-
Theres now a preference for it


-
3
-
-
To be clear, this can be chalked up as a bug to be honest.
Nerd ramble in the expandable below
SpoilerWe divide jobs here on line 229

Then on 324 (in the same function) we check if we should allocate highpop slots

The original implementation in 2018 (https://github.com/ParadiseSS13/Paradise/pull/8995) did it on roundstart for some reason, instead of before.
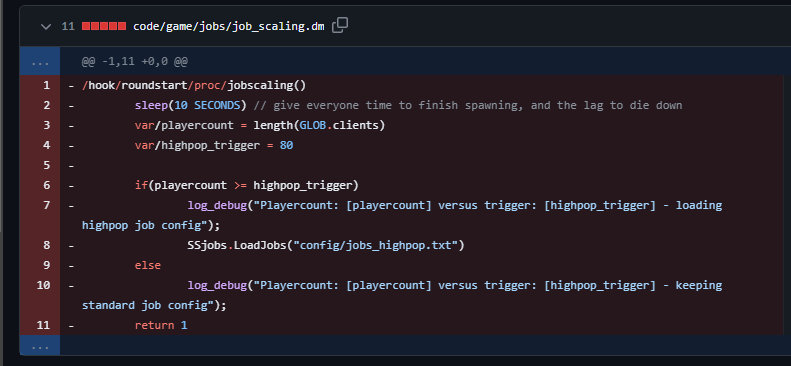
Sidenote - that sleep(10 SECONDS) is actually what caused all the roundstart lag but dont worry about it.
The highpop trigger is 80 clients.
Which is 15/24 hours of the day, damn near 2 thirds of it.
TLDR - This loads the highpop slots after the round has started, when really it should be before jobs are divvied out.
-
1
-
-
19 hours ago, Medster said:
Donation button being pushed off screen in my case
Solution - Dont have your taskbar on the side like a gremlin
That aside, I will fix things like the borg issue in due time, and I do want to make this as accessible as possible, its huge for the people who can use it, but I dont want to gimp the rest of the playerbase who cant. I have had one idea that is a best of both worlds but its also the most unreasonable thing in the world.
If you click on someone outside of the 15x15 with a gun for example you get something about "you can't focus your aim this far away!" or similar. Its a cludge but it satisfies a piece of the balance issue.
I am open to suggestions on how we sort this, since its a feature I want in, and a lot of other people do, but we cant impact the playerbase who dont play on 1080p. On that note I do want to profile what screen resolutions we get the most here, but I dont know of a good way to do that without snapping it with JS and something something GDPR. It would make for some nice figured I feel though.
-
1
-
-
1 hour ago, CinnamonSnowball said:
I would like to point out that every single radio chat message in your screencaps that isn't 2-3 words gets split into two lines. Considering common chatter more often than not is longer than that, you basically only got half the usual chat view compared to before.
This thread is going to make me start profiling for the average length of a chat message to see how it looks.
-
 1
1
-
-
This thread serves as a feedback container for https://github.com/ParadiseSS13/Paradise/pull/20861
Making it the only screen size is an issue because people on lesser monitors get a major issue with it, so I propose a toggle to go between 15x15, and 19x15, but everyone must accept its going to be a balance issue that some players may be on a larger screen size.
-
1
-
-
Right before I even go into the actual meat of this post I want to explain how the voting system actually works just to clear up any confusionwith it.
Internally, we have a tracking system for each PR which can have approvals or objections, under the category of design or balance. These objections can only be applied by the relevant teams (IE - Someone in balance team cant throw a design objection on a PR). The PR type depends on the votes needed (99% of them need the design team, Balance PRs need the balance team obviously). If you are a member of both teams and a PR needs both votes, you only get one.
It is not compulsory for a PR to get everyone to vote on it, if that was the case we would be here forever, hence why its on a majority system. However, if a PR has no approvals and only a singular objection, we tend to leave it open until expiration date (30 days) and nag people internally for votes just to make sure they havnt missed it.
It is a common occurance for someone's thoughts on a PR to be indifferent, as in they dont have it enough to object, but dont really approve of it, its just "meh" to them, hence no vote. A PR can go without approval but not have objections either.
I should point out all of this is outlined on https://paradisestation.org/dev/policy/
Now for the post itself.
6 hours ago, Bmon said:I have noticed a massive decrease in communication and transparency on the github ever since PR voting has been split into different design teams.
This is absolutely incorrect. The split into teams has bought on more people who are actually willing to write objections out onto PRs instead of hitting a button behind the scenes and not caring. If you take a before
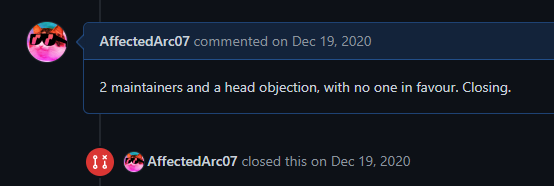
And an after
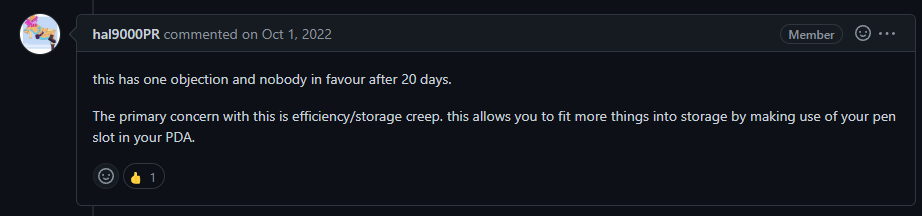
I really dont see the argument here
6 hours ago, Bmon said:There's no reason for our PR review process to be private, we are an open-source codebase.
When you wake up to 3 death threats (no this is not hyperbole) and nagging over the most minute of objections, you will see why sometimes we keep quiet about objections, especially if the PR is likely to get you absolutely slated for it. I also want to cite this from the GitHub code of conduct, specifically the first sentence.

It is also worth nothing we do ask people from the teams to try state their issues more
 7 hours ago, Bmon said:
7 hours ago, Bmon said:Do note the differences between visible and public. I am calling for all development channels to be made visible meaning that anyone can read them but not talk in them.
The PR tracker could potentially be opened up, but that will be a lot of tape crossing and policy changes. However, the internal development chat will never be opened up, purely because:
- Exploit discussion
- Discussion on disciplinary action on other GitHub contributors
- We really dont need the frothing masses berating us when we even think slightly about a possible rework
TLDR - The system itself isn't flawed and people did use to state objections, theres just been a dropoff of it with burnout among other things, and we are working on it.
-
1
-
Found the root cause

-
1
-
1
-
-
-
18 hours ago, NarrowlyAvoidingABan said:
Okay well no-cap i was just kicked or banned so check the audit logs lmfao
Unlinking your discord account auto kicks you.
I hate that this happens, but you were welcome to rejoin.
-
-
I have stepped down from headcoder, with @farie82 taking the spot
-
3
-
3
-
-
Wouldn’t really call myself an old player despite being here since 2016, largely due to the sheer number of bans (including an entire year one), as well as a 6 month break in 2019.
As for why am I still here, it gives me something to do as a hobby that doesn’t need astronomical time devotion, but I can still feel like I am making a difference hosting wise. It’s no secret I am right in the burnout phase given my lack of existence ingame, but hey the lights are still on so I’m calling that a job well done.
-
3
-
-
-
2 hours ago, LforLouise said:
Simply remove tcomms and employ assistants as message runners, or make Ian a carrier corgidgeon.
Alternatively make the little PDA room thingy near gravgen a coldroom and put tcomms in there - the PDA messaging server is already in it, so it would make some sense

The reason it *isnt* in here is because it makes it far too difficult for nukies and the likes to sabotage.
-
5 hours ago, Leanfrog said:
I also like the idea of it requiring a cold room but as mentioned above by others I feel it wouldn't change anything since science already starts with one, and it'd be very easy for them to just shove a new one down in there, but if it requires a cold room and has a reset period like in Miravel's post that seems fine and would encourage actually setting something secure up.
Could make it require a room away from servers due to interference or whatever
-
1
-
-
Marking as resolved
-
Mirror post
-
1
-
-
10 hours ago, Leanfrog said:
So, as it is currently whenever Tcomms or any other major thing goes down, RND is capable of just shitting out a new version almost immediately, we'll keep the focus of this on Tcomms for now as to keep things brief, for example, a terror or xeno sneaks onto the AI sat and destroys the Tcomms hub, at first glance this is a really bad thing people can't communicate anymore but OOOOPS, RND has just immediately built a new Tcomms hub with no repercussions for it going down and comms are back up with effectively no downtime.
So my suggestion is this, make Tcomms have a "rebooting" period whenever comms are taken offline, be it manually shut down or destroyed. This would enable the destruction of the Tcomms hub to actually be impactful, additionally this shouldn't affect Malf AI too much, the forced downtime of comms being shut off would reflect the usual bluff of "ions".
Overall a minor change that should still create a reasonable impact on how things go down this also eliminates the potential of people pre-building tcomms hubs to just shut down breaking comms even harder, if you were to ask me I'd say at base the downtime should be around 5 minutes but the period of downtime is up for debate.Absolutely.
My biggest mistake with new tcomms was making it so easy to repair.
I did at one point consider making the machine only able to operate in cold temperatures, but felt that may be too extreme. However, now the issue has been raised like this, I may consider it.
-
9
-
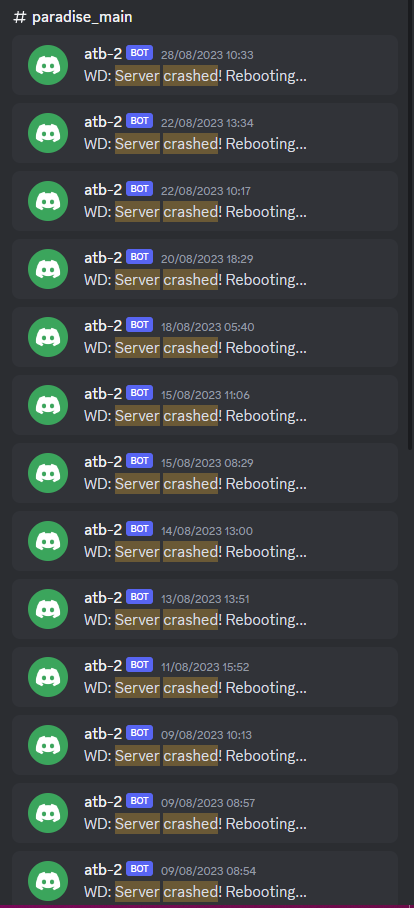
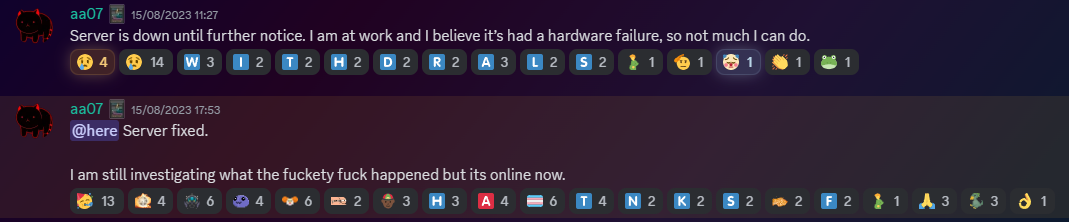
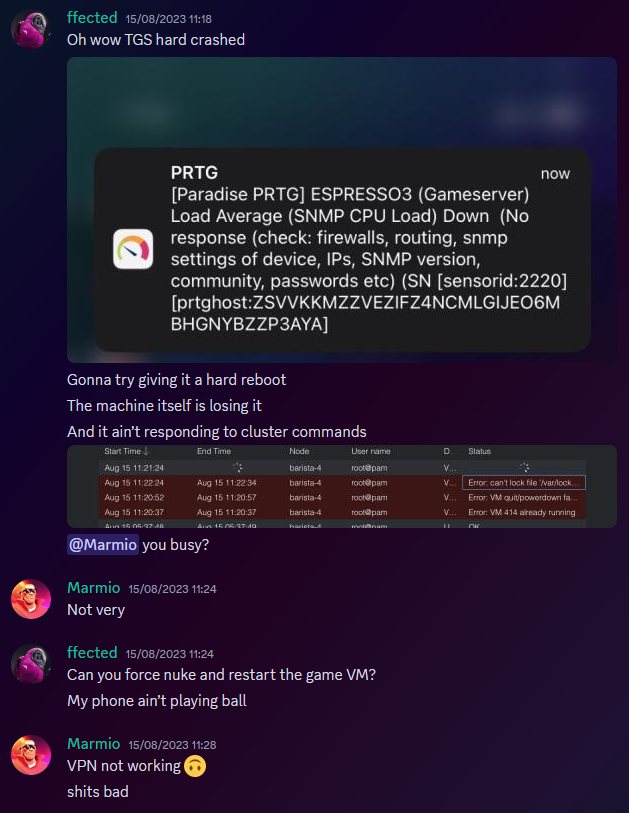


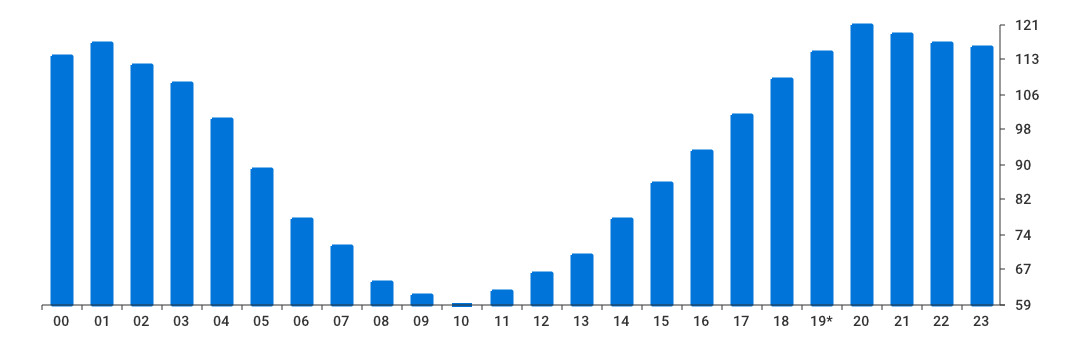





Where can I appeal for VPN whitelist?
in General Discussion
Posted
Correct, file a normal appeal and ill get to it